eTamu.id – Big Data Architecture: In the previous article about big data, we discussed what Big Data is. This article is a continuation of the previous article, if you haven’t read the article that reviews the Introduction to the Definition of Big Data, then you are required to read it first before reading this Big Data Architecture article.Â
Traditional Information Architecture Capabilities of Big Data
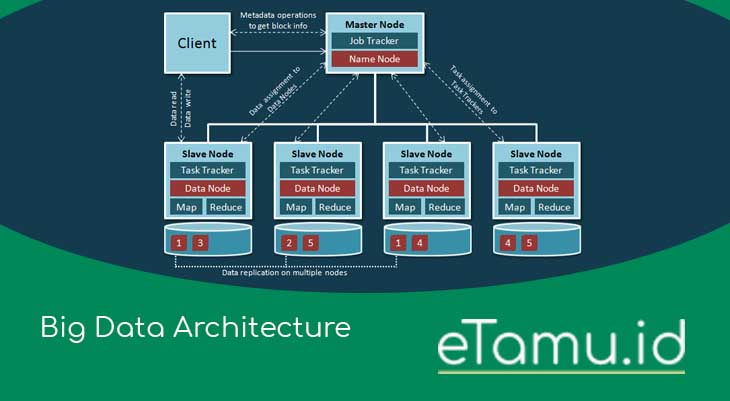
To understand the high level architectural side of Big Data, you must first understand the logical information architecture for structured data.Â
The figure below shows two data sources that use integration techniques (ETL/Change Data Capture) to transfer data to a DBMS data warehouse or operational data store, then try to provide various kinds of analytical power to present the data.Â
Some of the strengths of this analysis include, ;Â dashboards, reports, EPM/BI Applications, summary and query statistics, semantic interpretation of textual data, and visualization tools for dense data.Â
The most important information in the architectural principles includes how to treat data as an asset through the value, cost, probability, time, quality and accuracy of the data.Â
Adding Big Data CapabilitiesÂ
Describe the processing power for big data architecture, it takes a lot of things that need to be completed; volume, acceleration, variety, and value as demands. There are different technological strategies for real-time and batch processing purposes.Â
For real-time, put key-value data, such as NoSQL, it is possible to make it high performance, as well as index-based data retrieval. For batch processing, a technique known as Map Reduce is used, filtering data based on data specific to the discovery technique.Â
After the filtered data is found, then the data will be analyzed directly, entered into another unstructured database, delivered to a mobile device or integrated into a traditional data warehouse environment and correlated to structured data.Â
Also in addition to the new unstructured data, there are two key dissimilarities for big data. First, because of the size of the data set, raw data cannot be directly transferred to a data warehouse.Â
However, after the Map Reduce system there is a possibility that there will be a reduction in yield in a data warehouse environment so that it can use business intelligence reporting, statistics, semantics, and general correlation strengths.Â
It would be ideal to have analytical capabilities that combine Business Intelligence (BI) tools along with big data visualization and query power. Second, to facilitate analysis in the Hadoop environment, a sandbox environment can be created.Â
For some cases, big data needs to get data that is always changing and unpredictable, to analyze that data, new architectures are needed.Â
In a retail company, a good example is capturing traffic lanes in real-time for the purpose of placing store advertisements or promotions in strategic places that people walk by, checking the placement of goods and promotions, observing real-time customer movements and behavior.Â
In other cases, an analysis cannot be performed until it is linked to company data and other structured data.Â
Also as an example, analyzing customer feelings, getting positive or negative feedback from social media will have one value, but associating it with all types of customers (most profitable or even the least profitable) will provide more value.Â
So, to meet the needs required by big data Business Intelligence (BI), namely context and understanding. Using the ability of statistical and semantic tools will make it possible to be able to predict future possibilities.Â
An Integrated Information Architecture of Big Data
One of the challenges examined in the use of Hadoop in enterprises is the lack of integration with the existing Business Intelligence (BI) ecosystem. Today, traditional BI and big data ecosystems are separated, causing confusion for integrated data analysts.Â
Also in the end, this kind of thing is not ready for use by business users and general executives. Big data users who are trying to use it for the first time often write special code to move the processed big data results back to the database for reporting and analysis.Â
These choices may not be feasible and economical for an IT company. First, because it results in the distribution of one data and standards that are not the same, so the architecture affects the economics of IT.Â
Big data works on a stand-alone basis to enable redundant investment opportunities, and in addition, many businesses do not even have the staff and skills necessary to develop specialized jobs. The most appropriate choice is to integrate the results of big data into the data warehouse.Â
The power of information is in the power for association and correlation. So what is needed is the ability to bring together disparate data sources, processing needs together – the same in a timely manner and valuable analysis.Â
When various types of data have been acquired, that data can be stored and processed in traditional DBMSs, simple file systems, or distributed cluster systems such as NoSQL and Hadoop Distributed File Systems (HDFS).Â
In an architectural way, the critical component that breaks up that side is the integration layer that sits on the inside. That integration layer needs to extend to all data types and domains, and serve as a bridge between the new and traditional data receiving, and processing frameworks.Â
Data integration capabilities need to cover the full spectrum of speed and frequency. This is needed to overcome extreme needs and volumes that are always increasing. Therefore we need a technology that is very possible to integrate Hadoop/Map Reduce with data warehouses and transaction data.Â
The next layer is used to load the reduced results from big data to the data warehouse for further analysis. It also requires the power to connect with structured data such as customer profile info when processing or processing data in big data to obtain patterns such as detecting suspicious activity.
The results of data processing will be entered into traditional ODS, data warehouses, and data marts for further analysis such as transaction data. The additional component in this layer is Complex Moment Processing to analyze data flows in a real-time manner.Â
The business intelligence layer will be complemented by advanced analysis, in statistical database analysis, and advanced visualization, applied in traditional components such as reports, dashboards, and queries.Â
Governance, security, and operational management also cover the entire spectrum of the data and information landscape at the enterprise level.Â
With this architecture, business users do not see a single divider, nor are they even aware of the differences between traditional transaction data and big data.Â
The data and analysis flow will feel smooth without any hindrance when faced with various types of data and information sets, hypotheses, analysis patterns, and making decisions.Â
Big Data for development (Big Data for Development Interests)Â
Big Data for development purposes is related to, but not the same as ‘traditional Data development’ (eg survey data, official statistics), and the private sector and the mainstream media call it ‘Big Data’.Â
Big Data for Development sources usually have some/all of these features:
- Digitally generated, data that is generated digitally (as opposed to manually digitized), and can be stored using a series of ones and 0s, and in this way can be manipulated by a computer
- Passively produced, Data is data that is produced or a product of our daily lives or relationships with digital services.
- Automatically collected, data that is formed from operational data and transactions that have been collected and processed (ETL) and stored in a data mart
- Geographically or temporally trackable, Data – data that gives a place or position, for example data on the location of a cellphone or the duration of a call
- Continuously analyzed, information relevant to human welfare and development and can be analyzed in real-time
Use of Big Data in companiesÂ
- IT logs Analytics, Long-term Log Storage, used for ongoing system analysis to prevent and overcome failures in the system, use the results of log analysis to find and determine with certainty what failures occur in the system, prepare certain steps which can also be used as a solution to system problems.
- Fraud Detection Pattern, Widely used in the financial section or wherever financial transactions are involved, Optimizing the use of existing data to provide the power to detect fraud when a transaction is in progress
- The Social Media Pattern, the use of Big data for social media analysis and customer sentiment, gives power to companies to know customer desires in a broad way, get feedback in a direct way, and know immediately the effect of sentiment on sales, and the effectiveness and acceptance of customers in marketing what was done.
- Risk : Patterns for Types and Management, Providing the ability to fully use data and analysis in probability modeling and risk management to provide knowledge of opportunities and their handling in an appropriate and direct way
- Still Much More
Building Big Data PlatformsÂ
Like data warehousing, web shops or IT databases, infrastructure for big data has unique requirements.Â
In considering all the components of a big database, it is important to remember that the end goal is to easily integrate big data with your company data to enable you to perform in-depth analysis on unified data sets.Â
Requirements in Big Data Infrastructure
1. Data acquisitionÂ
The acquisition step was one of the big changes in infrastructure in the days just before big data.Â
Because big data refers to data streams with higher speeds and a variety of types, the infrastructure needed to support the acquisition of large data must be delivered slowly, predictably both in capturing data and in processing it quickly and simply.
Can handle very high transaction volumes, often in a distributed environment, and support flexible, dynamic data structures.Â
NoSQL databases are often used to retrieve and store big data. They are perfect for dynamic data structures and are highly scalable. Data stored in NoSQL databases are usually of various types/types because the system is intended to only capture all data without grouping and parsing data.Â
As an example, NoSQL databases are often used to collect and store social media data. When the applications that customers use frequently change, the storage arrangement is made simple.Â
Instead of building a schema with links between entities, a simple list often contains only the primary key to identify the data point, and then the content container holding the relevant data. This simple and dynamic layout allows changes to take place without any reorganization of the storage array.Â
2. Data OrganizationÂ
In the meaning of data warehousing classic, organizing data is called data integration. Because there is a very large volume/amount of data, there is a tendency to organize data in its original storage, thus saving time and money by not moving large volumes of data around.Â
The infrastructure needed to manage large amounts of data must be able to process and manipulate data in its original repository. Usually processed in batches to process large data, various formats, from unstructured to structured.Â
Apache Hadoop is a new technology that allows large volumes of data to be managed and processed while protecting data on native data storage clusters. The Hadoop Distributed File System (HDFS) is a long term storage system for site logs for example.Â
The site log changes to searching behavior by running the MapReduce program in the cluster and producing results that are collected in the same cluster. The results are compiled and then loaded into the relational DBMS system.Â
3. Data AnalysisÂ
Because data does not always move throughout the organizational phases, this analysis can also be performed in a distributed environment, where some data will reside where it was originally stored and transparently retrieved from a data warehouse.Â
The infrastructure needed to analyze large data must be able to support deeper analysis such as statistical analysis and data mining, on data of various types and stored in separate systems, providing faster response times driven by changes in behavior;Â as well as automate provisions based on the type of analyticsc.Â
Most importantly, the infrastructure must be able to integrate analysis on a mix of big data and traditional enterprise data. New insights come not only from new data analysis,
Challenges in using Big DataÂ
In the effort to use Big Data there can be many obstacles and challenges, many of which are related to data which involve the acquisition, sharing and privacy of data, and in data analysis and processing.
- Privacy, Privacy is the most sensitive information, with current plans, laws, and technology, Privacy can be understood in a broad sense as a company’s efforts to protect the competitiveness of their customers. The data that is used/stored is also big data
- Access and sharing Access to data, both old data and new data can be an obstacle in obtaining data for big data, especially in old data where stored data has different and varied forms or physical form, access to new data also requires more effort because permission and licenses are needed to connect to non-public data legally.
- Analysis Working with new data sources brings a number of analytic challenges, the relevance and severity of the challenges will vary depending on the type of analysis being performed, and on the type of decisions the data will ultimately be able to convey.
- Interpreting Data, Errors such as Sampling selection bias are things that are often found where the existing data cannot be used to represent the entire existing population, as well as apophenia, seeing that there is a pattern even though it doesn’t really exist because of the large amount of data, and errors in interpreting the relationships in the data.
- Defining and detecting anomalies, challenges the sensitivity of the monitoring system’s specificity. Sensitivity refers to the monitoring system’s ability to detect all problems it has been set to detect while specificity refers to its ability to detect only a few relevant problems. failure to achieve the ultimate “Type I regulatory error”, also known as a “false positive”; failure to obtain traces of a “Type II errorâ€, or “false negative.†Both of these unwanted errors when attempting to detect a malfunction or anomaly, however defined, for various reasons. False positives damage the credibility of the system while false negatives cast a penalty on their relevance.
Thus a Little Explanation about Big Data Architecture which is complemented by other things related to big data such as big data development, big data problems, and so on. Are you interested in big data? Let’s share and learn big data together on this blog.
Related post:
- Big Data Analysis: Why Is It Needed and Who Does It?
- Top 10 Best Big Data Tools and The 5Vs to Define the Tool
- How Big Data Helps Companies Grow Faster! Here is The Fact
- Big Data Marketing: The Role in Developing a Company’s Strategy
- Content Intelligence: Improve Quality of Content Marketing Strategy
- 10 Content Marketing Tools that Marketers Need to Master

- TikTok Analytics: Bagaimana Cara Menggunakannya? Tips Pemula - July 17, 2026
- Content Intelligence: Improve Quality of Content Marketing Strategy - June 15, 2026
- Podcast Marketing, Strategies to Make Your Podcast More Popular - June 14, 2026